
It started with a big question…
How do people talk about their jobs online?
The Bruckman Lab @ Georgia Tech seeks to understand how people use online communities in a variety of ways.
With news circulating surrounding Starbucks’ unionization attempts, members of my lab group wondered what it meant to be able to use online platforms like Reddit and Discord to connect with people who worked the same job as you, even if they were thousands of miles away.
A Tale of 2 Papers
We explored this question first by conducting qualitative interviews with Starbucks workers across the country, hoping to better understand how they used online platforms to communicate with each other.
We found that job satisfaction was correlated with having stronger interpersonal connections across the company — common issues like a lack of shifts and handling emotional labor associated with the job were ameliorated with strong social connections in the workplace.
From this research, we produced the paper: Metrics and Macchiatos: Challenges for Service-Industry Workers and the Need for Worker-Driven ICTs
Once that paper was finished, I began to wonder more… so many people we talked to had big issues with their jobs, and Starbucks had consistently been named one of the top service-industry employers to work for by companies like Forbes, but it seemed that deeper under the surface, it wasn’t always what it appeared.

So What Now?
Why Subreddits?

This insight led to the development of the 4 main research questions for my undergraduate thesis, that is:
1. How do low-wage workers discuss their work in online communities?
2. What are the most common sentiments for low-wage workers surrounding their work?
3. What topics encourage people to post positively or negatively?
4. How do these sentiments compare to what a corporate ranking might say about the work?
Unlike our previous research, this question could not be answered with qualitative interviews alone, requiring me to learn Natural Language Processing (NLP) — a subset of the larger field of Machine Learning (ML) within computer science.
My thesis aims to answer these questions through a field of NLP called sentiment analysis — which provides a quantitative model for understanding emotions in text online.
I identified 5 top companies listed as being “Great Places to Work” and have begun scraping posts, comments, and interactions from their respective employee subreddits.
A couple of reasons!
I have previous experience working with employee subreddits from the first paper mentioned above
Reddit’s API is one of the few still accessible for researchers
Reddit has lots of historical data accessible since many of these subreddits have been active for years — allows for time analysis as well as sentiment analysis
Great question!
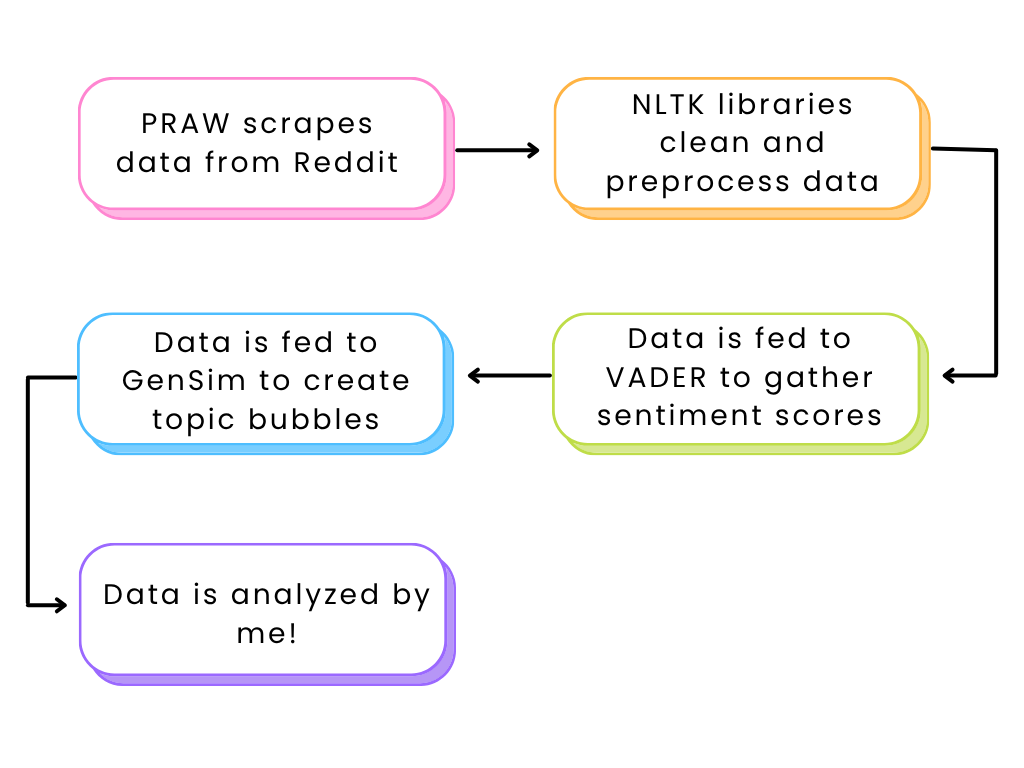
My research utilizes Python libraries like:
PRAW - Reddit scraper
NLTK - NLP toolkit
VADER - Sentiment analysis library keyed for social media posts
GenSim - Creates topic ‘bubbles’ for most commonly seen keywords
Together, these libraries create a flow like so:
There’s been a few key findings so far!
News surrounding companies studied heavily influence what topics subreddits discussed — we understood this from our first Starbucks paper, where unionization news meant an uptick in more negative posts related to topics like union busting.
Subreddits (so far) have not been as negative as I had originally hypothesized — while many people utilized these platforms to vent frustration, others responded and offered support, or chatted about the parts of their job that they did really like.
Less so about the research, but I learned the importance of an external hard drive after I lost part of my code base to an unfortunate water bottle incident…
Check out some sample findings!
While you’ll have to wait until December to see my full thesis and findings, I put together a sample of findings to help others visualize my work.
For this sample, I pulled the 500 latest (as of June 2025) posts and their respective comments from r/starbucksbaristas to illustrate how sentiment scoring and topic modeling work

This sample compounded overall positive in sentiment!

This is what a topic modeling distribution looks like — these are the keywords for the topic of shift swapping/scheduling
How does your code work?
What have you found so far?